Back in January, we started looking at AI and how to run a large language model (LLM) locally (instead of just using something like ChatGPT or Gemini). A tool like Ollama is great for building a system that uses AI without dependence on OpenAI. Today, we will look at creating a Retrieval-augmented generation (RAG) application, using Python, LangChain, Chroma DB, and Ollama. Retrieval-augmented generation is the process of optimizing the output of a large language model, so it references an authoritative knowledge base outside of its training data sources before generating a response. If you have a source of truth that isn’t in the training data, it is a good way to get the model to know about it. Let’s get started!
Your RAG will need a model (like llama3 or mistral), an embedding model (like mxbai-embed-large), and a vector database. The vector database contains relevant documentation to help the model answer specific questions better. For this demo, our vector database is going to be Chroma DB. You will need to “chunk” the text you are feeding into the database. Let’s start there.
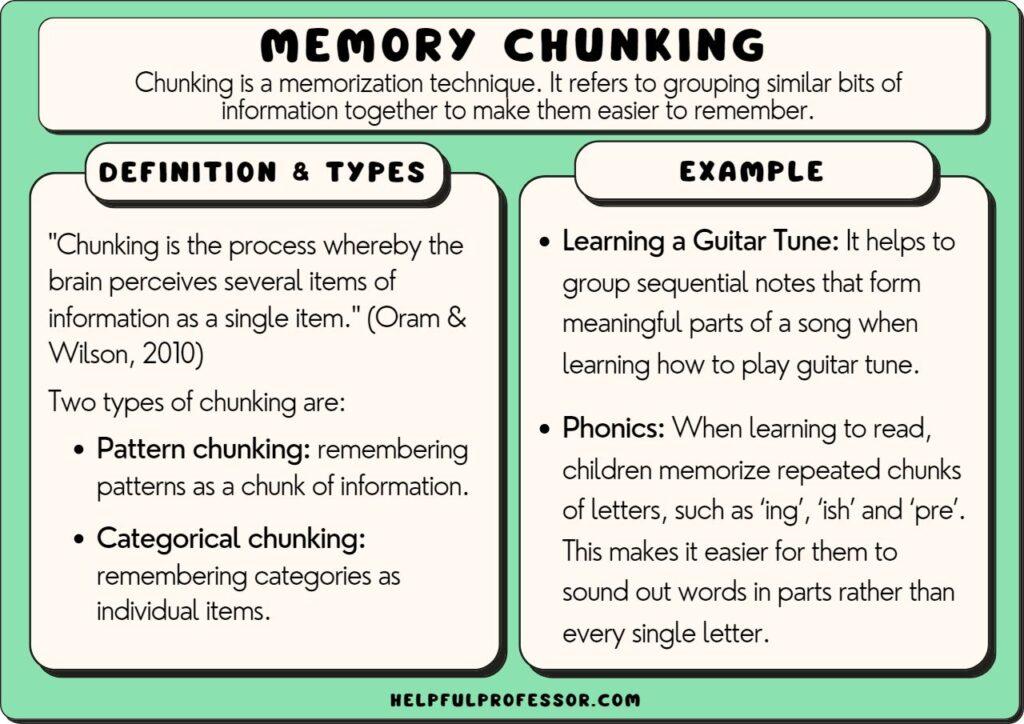
Chunking
There are many ways of choosing the right chunk size and overlap but for this demo, I am just going to use a chunk size of 7500 characters and an overlap of 100 characters. I am also going to use LangChain‘s CharacterTextSplitter to do the chunking. It means that the last 100 characters in the value will be duplicated in the next database record.
The Vector Database
A vector database is a type of database designed to store, manage, and manipulate vector embeddings. Vector embeddings are representations of data (such as text, images, or sounds) in a high-dimensional space, where each data item is represented as a dense vector of real numbers. When you query a vector database, your query is transformed into a vector of real numbers. The database then uses this vector to perform similarity searches.
You can think of it as being like a two-dimensional chart with points on it. One of those points is your query. The rest are your database records. What are the points that are closest to the query point?
Embedding Model
To do this, you can’t just use an Ollama model. You need to also use an embedding model. There are three that are available to pull from the Ollama library as of the writing of this. For this demo, we are going to be using nomic-embed-text.
Main Model
Our main model for this demo is going to be phi3. It is a 3.8B parameters model that was trained by Microsoft.
LangChain
You will notice that today’s demo is heavily using LangChain. LangChain is an open-source framework designed for developing applications that use LLMs. It provides tools and structures that enhance the customization, accuracy, and relevance of the outputs produced by these models. Developers can leverage LangChain to create new prompt chains or modify existing ones. LangChain pretty much has APIs for everything that we need to do in this app.
The Actual App
Before we start, you are going to want to pip install tiktoken langchain langchain-community langchain-core. You are also going to want to ollama pull phi3 and ollama pull nomic-embed-text. This is going to be a CLI app. You can run it from the terminal like python3 app.py "<Question Here>".
You also need a sources.txt file containing the URLs of things that you want to have in your vector database.
So, what is happening here? Our app.py file is reading sources.txt to get a list of URLs for news stories from Tuesday’s Apple event. It then uses WebBaseLoader to download the pages behind those URLs, uses CharacterTextSplitter to chunk the data, and creates the vectorstore using Chroma. It then creates and invokes rag_chain.
Here is what the output looks like:
The May 7th event is too recent to be in the model’s training data. This makes sure that the model knows about it. You could also feed the model company policy documents, the rules to a board game, or your diary and it will magically know that information. Since you are running the model in Ollama, there is no risk of that information getting out, too. It is pretty awesome.
Have any questions, comments, etc? Feel free to drop a comment, below.
https://jws.news/2024/how-to-build-a-rag-system-using-python-ollama-langchain-and-chroma-db/
#AI #ChromaDB #Chunking #LangChain #LLM #Ollama #Python #RAG