
Now, it's time for me to officially move away from IDA to #Ghidra everything I have. I will start with Magic Strings, then move to port #Diaphora.
#Diaphora
Thank you very much to the person that donated 100 euros to the #Diaphora project, it's highly appreciated!
The Reverse Engineering community has spoken. #Diaphora will be ported to #Ghidra in the next months. I would love to have it working properly by the end of the year, but I cannot be sure. So, no ETA for now.
Thank you very much to the person that donated 25 euros to #Diaphora!
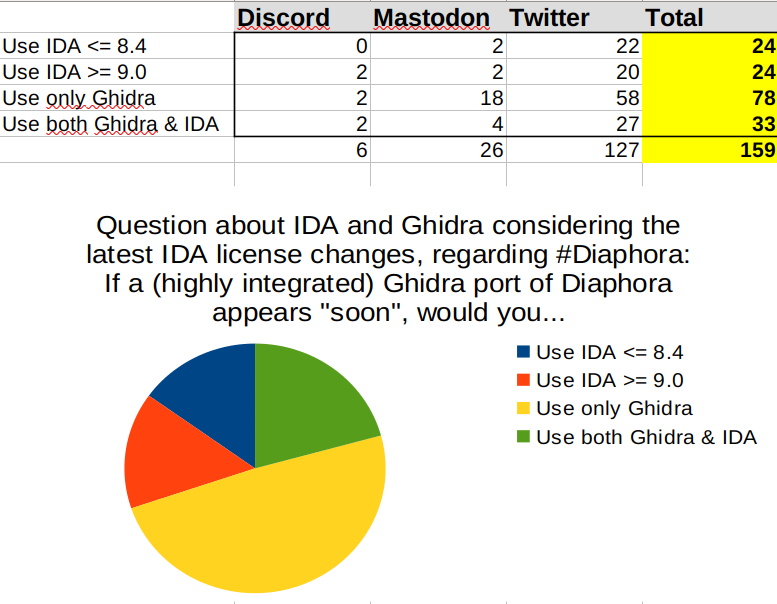
Question about IDA and Ghidra considering the latest IDA license changes, regarding #Diaphora: If a (highly integrated) Ghidra port of Diaphora appears "soon", would you...
Let me explain you the idea and the problem.
The Idea: Put a service for functions signatures using #Diaphora technologies online or a SQLite database file that can be easily downloaded somewhere for offline usage.
The Problem: Github doesn't allow files bigger than 100 MB. The initial signatures database I have is 1,2 GB, but it will grow a bit (I don't think it will be ever over 10 GB in years and years).
That explained, any recommendation about how to solve this problem with my resources?
What is a *cheap* way to put an online service that requires a database that will be under ~10 GB for a number of years? If it's free, better.
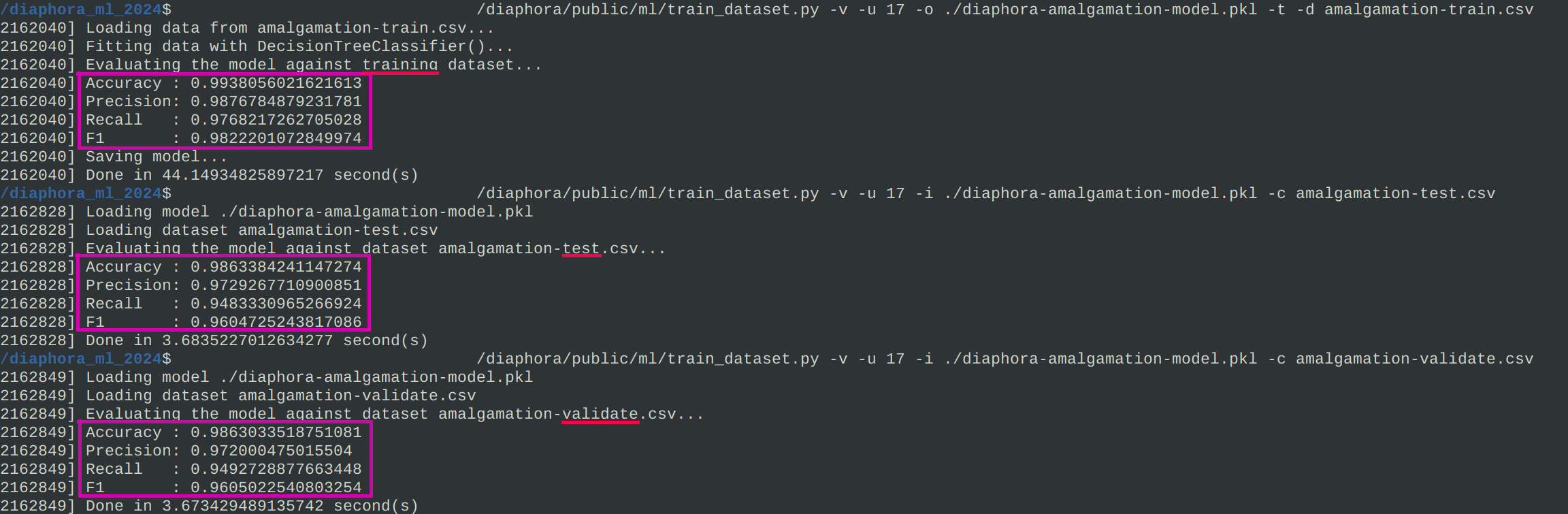
I haven't published a new #Diaphora release just yet because the code is still a bit experimental and there are some problems that I'm trying to fix like, for example: SciKit Learn distributed models cannot be used if the version of the training machine and the machine where it's being used (where Diaphora runs) are different.
The code is also published (in github) already and #Diaphora now can use an already trained model to try to improve binary diffing results (matching). I haven't made yet a new release just yet as these changes are considered a bit experimental for now.
The datasets and tools for training and testing are here: https://github.com/joxeankoret/diaphora-ml
And Diaphora, is here: https://github.com/joxeankoret/diaphora
#Diaphora #BinaryDiffing #Bindiffing #ReverseEngineering #MachineLearning
Here are the slides of my "Simple Machine Learning Techniques for Binary Diffing (with Diaphora)" talk given at the @44CON conference last week:
https://github.com/joxeankoret/diaphora-ml/blob/main/docs/diaphora-ml-techniques-44con-final.pdf
#44con #Diaphora #MachineLearning #ReverseEngineering #BinaryDiffing
So, a classifier trained over the #Diaphora testing suite + the Cisco Talos Dataset-2 binaries works pretty well. More details on my talk next week at #44con
Thank you very much to the anonymous person who donated 100 euros to #Diaphora!
Why diff only assembly when you are using a decompiler for your work? #Diaphora
Grrrr... I still cannot find a model that fits all use-cases.

In case you are curious, I'm building a dataset out of cross comparison of the binaries in "Dataset-2" from this #Cisco #Talos dataset: https://github.com/Cisco-Talos/binary_function_similarity
The final idea is to train a model using the generated dataset (a simple CSV file) and then use it with #Diaphora.
PS: The cross comparison is only done *if* the binaries look to be the same.
Before optimising this thing, it used to foresee that for processing the same dataset it would take like ~2720 hours, and now around ~4 hours. This is acceptable. Finally. #Diaphora
>[Diaphora: Sun Sep 8 19:05:33 2024] Elapsed 0:02:59 second(s), remaining time ~4:08:39
I have just stumbled upon this post diffing some windows driver:
https://www.crowdfense.com/windows-wi-fi-driver-rce-vulnerability-cve-2024-30078/
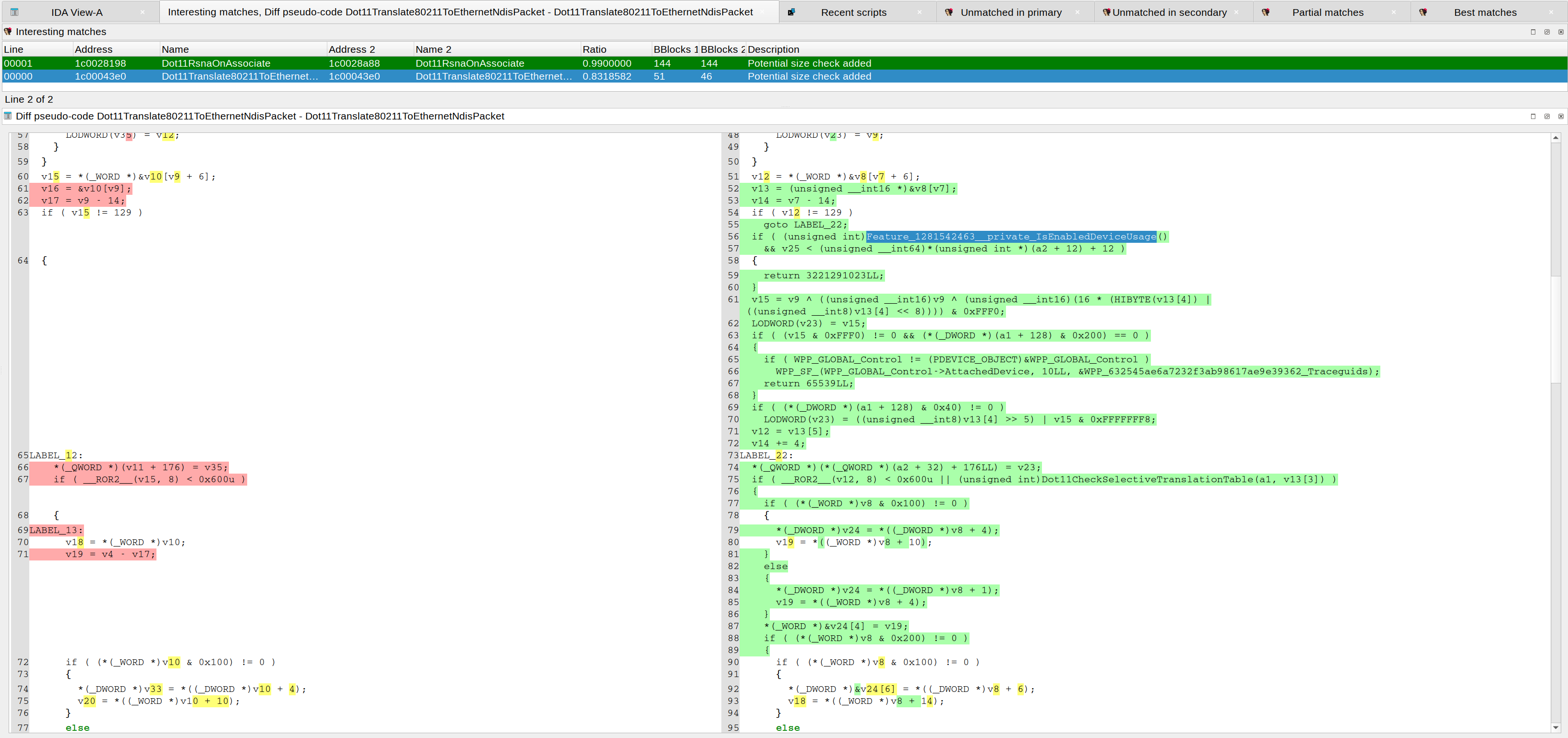
Why use #BinDiff and see this [first picture] when you can use #Diaphora and see this [second picture]?
Of course, feel free to use whatever tool you prefer but, what's the point of doing more work? Diaphora finds out that only 2 functions are interesting for patch diffing and shows exactly, in the pseudo-code, what new chunk of code was added and what new function is being called. Diffing decompilation.

I had 3 potential ideas to apply machine learning techniques in #Diaphora:
1) Train a model with known good matches (best & partial) to try to improve results for less reliable heuristics.
2) Train a gigantic model with matches between binaries with and without symbols for GCC, Clang and MSVC, for Linux, Mac and Windows.
3) Train a model using versions of a same binary with symbols and without symbols, and then predict symbols in future versions without symbols.
Guess which one(s) got working?
Not bad results for a real use-case. #Diaphora #MachineLearning
![Output of the tool for training models for Diaphora usage:
$ ./train_dataset.py -v -u 17 -o mpengine-model.pkl -i mpengine-model.pkl -d mpengine-snapshot.csv -t -c mpengine.csv --graphviz
[Diaphora: Fri Aug 30 15:40:19 2024 373711] Loading data from mpengine-snapshot.csv...
[Diaphora: Fri Aug 30 15:40:21 2024 373711] Fitting data with DecisionTreeClassifier()...
[Diaphora: Fri Aug 30 15:40:23 2024 373711] Evaluating the model against training dataset...
[Diaphora: Fri Aug 30 15:40:23 2024 373711] Accuracy : 1.0
[Diaphora: Fri Aug 30 15:40:23 2024 373711] Precision: 1.0
[Diaphora: Fri Aug 30 15:40:23 2024 373711] Recall : 1.0
[Diaphora: Fri Aug 30 15:40:23 2024 373711] F1 : 1.0
[Diaphora: Fri Aug 30 15:40:23 2024 373711] Saving model...
[Diaphora: Fri Aug 30 15:40:23 2024 373711] Loading model mpengine-model.pkl
[Diaphora: Fri Aug 30 15:40:23 2024 373711] Loading dataset mpengine.csv
[Diaphora: Fri Aug 30 15:40:29 2024 373711] Evaluating the model against dataset mpengine.csv...
[Diaphora: Fri Aug 30 15:40:31 2024 373711] Accuracy : 0.9999633335879612
[Diaphora: Fri Aug 30 15:40:31 2024 373711] Precision: 0.9999644803114366
[Diaphora: Fri Aug 30 15:40:31 2024 373711] Recall : 0.9998224267865641
[Diaphora: Fri Aug 30 15:40:31 2024 373711] F1 : 0.9998934485036618
[Diaphora: Fri Aug 30 15:40:31 2024 373711] Done in 11.92996072769165 second(s)
[Diaphora: Fri Aug 30 15:40:31 2024 373711] Loading model...](https://files.mastodon.social/media_attachments/files/113/051/310/163/520/603/original/f8b5537b20d5b2ee.png)

With this data, I think I know which algorithm is the best fit for my use-case.
BTW, I'm surprised with the difference in times between the top 4 performing algorithms: most algorithms take more than 1 hour, but the decision trees classifier takes around 12 minutes.

Client Info
Server: https://mastodon.social
Version: 2025.07
Repository: https://github.com/cyevgeniy/lmst